The FemSMA Corpus Workbench is a tool for
- browsing.
- searching, and
- annotating
Screen Layout
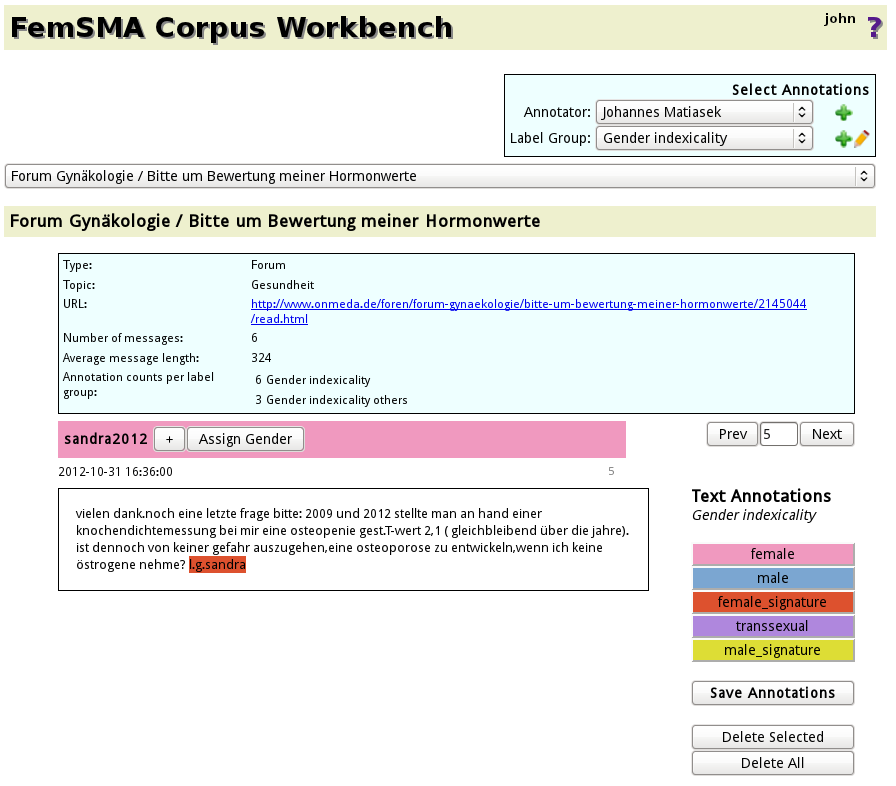
Annotation Selector
The annotation selector allows for specifying which annotations
are to be displayed. Annotations are organized in
label groups,
the Annotator is the person that created the annotation.
There exist two 'pseudo-annotators', Automatic and
All:
- ALL is preferably to be used when displaying search results, where it is desirable to view all existing annotations,
- Automatic is selected when viewing the Tokens pseudo label group (see Tokenization section)
Resource Selector
Documents are organized as resources, grouped together from where they
have been downloaded.
When selecting a resource, a resource description with some statistics,
and the first document of the resource is displayed.
There exist three 'pseudo-resources':
There exist three 'pseudo-resources':
- SEARCH: opens a window to specify search critery
- LAST SEARCH RESULTS: displays the results of the last document search
- LAST ANNOTATION LIST: displays a clickable list of the results of the last annotation search.
Document Annotation Display
The document display shows
- A user description (colored with the assigned gender of the user, if available. In case of several gender assignments, majority voting is used): When clicking on the button labeled '+', more user information is displayed. It is also possible to initiate a search for all postings of this user with a single click.
- The (possibly annotated) document
- Text annotation buttons (these are only displayed if a label group is selected)
 button right of the annotator selector.
In the for that appears enter the full name and the login of the
new annotator. Don't forget to click the 'Add' button, otherwise the
data will not be entered into the database.
The form can also be removed without adding a new annotator by clicking
button right of the annotator selector.
In the for that appears enter the full name and the login of the
new annotator. Don't forget to click the 'Add' button, otherwise the
data will not be entered into the database.
The form can also be removed without adding a new annotator by clicking